― 中で何が起きているのかを、例え話で解きほぐす ―
RAG(Retrieval-Augmented Generation)はよく、
「AIが社内ドキュメントを読めるようになる仕組み」
のように説明されます。
ただ、この理解だけで実装を始めると、だいたい途中で詰まります。
- 思ったほど精度が出ない
- 関係ない情報を持ち出す
- 回答がブレる
- 「RAGなのに嘘をつく(それっぽいけど根拠が違う)」
なぜかというと、RAGの正体は“1つの技術”ではなく、複数の設計判断の集合体だからです。
本質は「検索してから答える」という、人間の調べ物プロセスをどこまで機械で再現するかにあります。
この記事では、RAGを 内部で何が起きているか という視点で分解し、例え話を使いながら直感的に理解できるように整理します。
エンジニア以外でも読める一方で、実装前提の人が 設計判断できる深さまで踏み込みます。
1. RAGを一言で言うと何か?
RAGとは、
「人間が資料を探してから答える行為を、機械で再現したもの」
です。
人間の場合を考えてみる
職場で、こう聞かれたとします。
「欠勤控除ってどういう扱いでしたっけ?」
あなたは、だいたいこう動くはずです。
- 就業規則の“ありそうな場所”を思い出す
- それっぽい資料を何冊か開く
- 該当しそうな章を読む
- 書いてある内容を要約して答える
RAGは、この行動をそのまま機械化します。
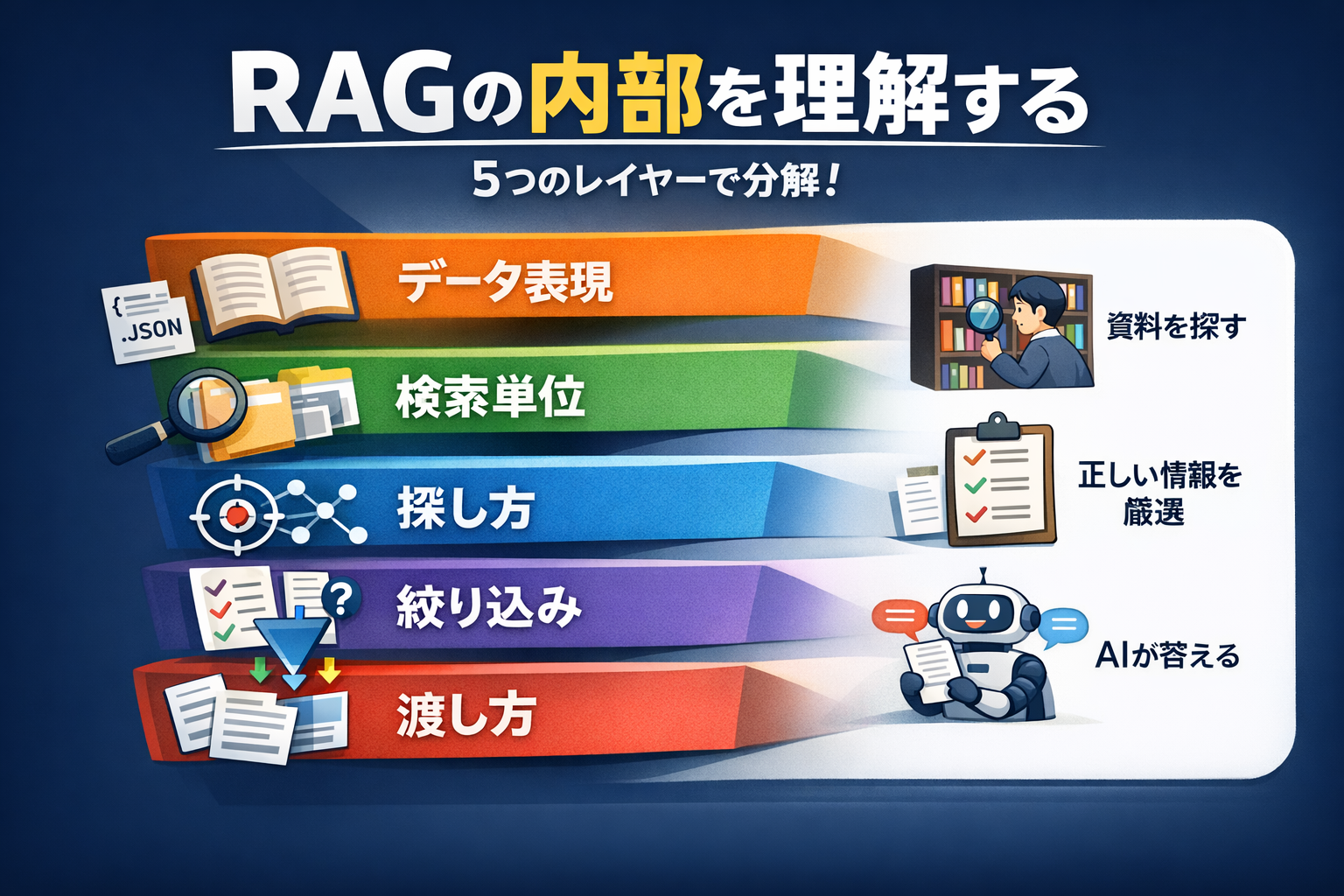
2. RAGの内部は「5つのレイヤー」に分かれている
RAGは内部的に、次の5層で構成されます。
Layer 1: データの表現(どう整理して覚えさせるか)
Layer 2: 検索単位(何を1件として探すか)
Layer 3: 探し方(どうやって探すか)
Layer 4: 絞り込み(どれを採用するか)
Layer 5: 渡し方(どうLLMに読ませるか)よくある誤解として、「RAGの種類」というと“ベクトルDBの違い”みたいに語られがちですが、実態は違います。
各レイヤーでどの選択をするか、その組み合わせが「あなたのRAG」です。
以降は、レイヤーごとに「何を決めているのか」をほどいていきます。
3. Layer 1:データの表現(どう整理して覚えさせるか)
―「資料の置き方」で精度は決まる
例え話:倉庫の整理
同じ荷物でも、
- 箱に何も書いていない倉庫
- 「工具」「書類」「食品」とラベル付きの倉庫
では、探すスピードも正確さもまるで違います。RAGでも同じです。
3-1. 生テキスト型RAG(まず動くが、当たり外れが大きい)
- PDF / JSON / Markdownなどを
- そのまま文字列にしてEmbeddingする
特徴
- 実装は簡単
- ただしノイズも混ざりやすい(目次、ヘッダ/フッタ、脚注、表の崩れ、重複など)
たとえるなら、段ボールに全部突っ込んだ倉庫です。
「あるにはある」けど、探す側(検索・モデル)が苦労します。
3-2. 構造付加型RAG(おすすめ:意味のラベルを足す)
Embeddingする前に、意味が分かるラベルを付ける方式です。
例(概念的な整形):
TITLE: 就業規則
SECTION: 欠勤控除
RULE: 欠勤控除は1日単位で控除
EXCEPTION: 半休は0.5日なぜ効くのか?
Embeddingは「単語」よりも「意味の方向性」で近さを測ります。
このとき「これはタイトル」「これはルール」「これは例外」といった情報があると、質問との対応が強くなります。
たとえるなら、棚にラベルを貼った倉庫。
検索が当たりやすく、後工程(LLM)も読み取りやすくなります。
4. Layer 2:検索単位(何を1件として探すか)
―「何を1件として探すか」で、RAGの用途が決まる
例え話:本を探すとき
- 「どの本を読むべきか」を知りたい
- 「本の中のこの1ページを知りたい」
この2つは、探す“粒度”が違います。RAGも同様です。
4-1. ファイル単位RAG(1ファイル = 1ベクトル)
できること
- 「この質問なら、この資料が怪しい」という“資料ナビ”
向いている用途
- 読むべきドキュメントの特定(FAQ候補提示、資料誘導、参照先の案内)
たとえるなら、まず“本棚(どの本か)”を当てるRAGです。
4-2. チャンク単位RAG(ファイルを分割して検索)
できること
- 回答文をその場で生成しやすい
- 「この段落に書いてある」と根拠を示しやすい
難しさ
- 分割(チャンク)の仕方が悪いと意味が壊れる
- 例:定義と例外が別チャンクに割れる
- 例:表の行が切れて文脈が欠落する
たとえるなら、本の中の“ページ(段落)”を探すRAGです。
4-3. 階層型RAG(本 → ページの2段階)
Step 1: 本(資料)を探す
Step 2: 本の中のページ(チャンク)を探す人間の探し方に最も近い形です。
「まず候補の資料を絞ってから、その中を丁寧に探す」ので、精度とコストのバランスが取りやすいです。
5. Layer 3:探し方(どうやって探すか)
―「全部探すか、近そうなところだけ見るか」
例え話:人探し
- クラス全員に声をかける
- 「あの人はこの辺にいそう」と当たりを付ける
規模が小さいなら前者でも成立しますが、人数が増えるほど後者が必要になります。
5-1. 全探索RAG(Brute force)
- 全ベクトルと比較する
- 正確(取りこぼしが少ない)
- 件数が増えると遅い
たとえるなら、小さなクラスなら全員に聞ける、という話です。
5-2. 近似探索RAG(ANN: Approximate Nearest Neighbor)
- 「だいたい近い」を高速に探す
- 代表例:IVF / HNSW など
たとえるなら、町内会・市区町村レベルになったら当たりを付けるしかない、という話です。
実務のRAGは、データが増えるほどANNが基本になります。
6. Layer 4:絞り込み(どれを採用するか)
―「候補をどう選ぶか」で、精度が跳ねる
例え話:採用面接
- 書類選考だけで決める
- 書類 → 面接 → 最終判断
後者のほうが手間はかかりますが、ミスマッチは減ります。RAGも同じです。
6-1. Single-stage RAG(1段で決める)
- 検索結果(上位k件)をそのまま使う
たとえるなら、書類選考だけです。
軽いけれど、運が悪いと関係ない候補が紛れます。
6-2. Two-stage RAG(Rerankで再評価する)
- いったん多めに集める(例:上位50件)
- その中を再評価して厳選(例:最終的に上位5件)
たとえるなら、面接付き採用。
ここを入れるだけで「それっぽいけど違う」が大きく減ることが多いです。
7. Layer 5:LLMへの渡し方(どう読ませるか)
―「提示の仕方」で、LLMの迷い方が決まる
例え話:持ち込み可の試験
- 資料持ち込み可(ただし範囲が広すぎると迷う)
- 「この資料だけを根拠に答えよ」(根拠が明確になる)
LLMも同様で、“何を根拠にしていいか”が曖昧だと、良くも悪くも想像してしまうことがあります。
7-1. 生注入型(そのまま貼る)
- 検索結果をそのままプロンプトに貼る
- 手軽だが、長くなるほどモデルが迷いやすい
7-2. 要約注入型(圧縮して渡す)
- 要約して渡す
- トークン節約になる
- ただし情報欠落のリスクがある(要約の時点で“落ちる”)
7-3. 根拠制約型(Grounded:根拠を固定する)
- 「以下の情報のみを根拠に答えよ」を強く指示する
- 引用(根拠の提示)を必須にする
- 情報が足りない場合は「不足」と言わせる
業務RAGで一番重要になりやすいのがここです。
たとえるなら、採点者が“根拠の出典”まで確認する試験にするイメージです。
8. RAGは「1つの技術」ではない
RAGはこう捉えると一気に分かりやすくなります。
RAG = 本の整理方法 × 探し方 × 選び方 × 読ませ方
だから、
- RAGを入れたのに精度が出ない
- RAGなのに嘘をつく(根拠がズレる)
という現象は、だいたい どこかのレイヤーの設計がズレているだけです。
「RAGを入れたかどうか」ではなく、「どのレイヤーをどう設計したか」が勝負になります。
まとめ:RAGは“人間の調べ物”の再現度を設計する技術
RAGとは、
「AIに資料を渡す仕組み」ではなく、 「人間の調べ物のプロセスを、どこまで再現するか」を設計する技術
です。
実装は、その後です。
まずは5レイヤーのどこで何を選ぶかを言語化できると、RAG開発は途端に安定します。
このシリーズを順番に読む
シリーズ: RAGシリーズ
ベクトルの基礎理解からRAG設計、最小実装イメージまでをつなげて読むシリーズです。
- AIのベクトルとRAGを香水で理解する
- 精度が伸びるRAG設計:重要な5レイヤー(この記事)
- 最小RAGを作ると中身はこうなる
前の記事: AIのベクトルとRAGを香水で理解する
次に読む: 最小RAGを作ると中身はこうなる

コメント